- The Atomic Builder
- Posts
- The Field Guide to Piloting Agents That Actually Ship
The Field Guide to Piloting Agents That Actually Ship
The gap between agent hype and enterprise reality - and how to close it
Faisal Shariff
October 21, 2025
Three weeks ago, a CTO showed me an agent his team had built. It could look up customer orders, check refund eligibility, and draft approval requests. Technically, it worked. Then he asked: "Should we actually let it run?"
That pause, between can and should, is historically, where most agent pilots die.
OpenAI's recent Dev Day made one thing plain: agentic capability is no longer a lab experiment. It's being bundled into platforms and now built-in.
This is your field guide to answering "should we?" with enough rigour that you can actually say yes.
We’re launching AgentKit, a complete set of tools for enterprises to build, deploy, and optimize agents.
The Shift No One's Explaining Clearly
Here's what’s changing: chatbots told you things. Agents do things for you - they draft the email, update the record, trigger the refund, route the ticket.
Which sounds great until you're in the room and someone asks: "What if it updates the wrong record?" or "Who's liable if it violates a policy?"
Your job as a product or transformation leader isn't to ship a flashy demo. It's to prove value, contain risk, and keep a clean audit trail so the post-mortem never needs to happen. That's the difference between a pilot that scales and one that gets pulled in week three because no one thought about rollback.
Agents don't fail because the technology breaks. They fail because no one defined what 'safe enough' looked like before pressing go.
Three Promises You Make on Day Zero
Before your teams connect a single API or write a single rule, get your stakeholders to agree on three things:
We will move one number in 30 days.
Not "explore" or "learn." Target a KPI. Maybe it's 20% faster resolution time, or 30% deflection on your top five support intents, or five fewer hours per week chasing invoice approvals. If you can't name the number, you're not ready to consider a pilot.The agent cannot take irreversible actions without a human in the loop.
"Irreversible" is the key word. Drafting an email? Reversible. Sending it? Depends. Issuing a £500 refund? That needs approval. Deleting a customer record? Absolutely not (yet!).Everything is logged, and we can roll back in one click.
If quality drops or something breaks, you don't want to be untangling API calls at 11 PM. You want a version history and a revert button. Your auditor will ask for this. Your ops lead will thank you for it.
If this sounds like change management with a new label, that's because it is. Agents don't fail technically, they fail organisationally, when no one defined what "safe enough" meant before go-live.
The Action Ladder: How to Scope Without the Hype
Some teams get stuck because they're asking the wrong question. They ask: "Can the agent do this?" What they should ask is: "At what rung of the ladder does this action belong?"
Here's the ladder: Answer → Retrieve & cite → Propose next step → Act with approval → Act within limits

The Action Ladder
You move to the next rung only when the action is reversible, data access is locked down, and you've hit your pass/fail bar in testing.
I watched a pilot hit the skids after two weeks because the agent had "view all customer data" access from day one. It never misused it - but when Legal audited the logs, they couldn't prove it hadn't accessed records outside the pilot scope. The initiative paused, not because of what the agent did, but because no one had scoped what it was allowed to do.
Modern platforms like OpenAI's AgentKit are finally packaging the boring-but-essential bits - versioning, approvals, guardrails, embedded UI, evals - so you're not building access control from scratch. Use them.
The Decision Matrix: 60 Seconds in Steering
You're in the steering meeting. Someone asks: "Should we let the agent actually do this, or just suggest it?" Think of the use case you’re exploring in terms of the matrix below. Ask yourself where it sits, to define the risk.
High impact + reversible? Let it act within limits (quotas, scopes, thresholds).
High impact + not reversible? Keep it at propose + human approval.
Low impact + reversible? Sandbox for autonomy.
Low impact + not reversible? Don't automate yet.
If you can't place the use case cleanly in one of these quadrants in under 60 seconds, it's not ready. Which probably means you need to halve the scope.

The Decision Matrix
So Where Do You Actually Start?
Pick something low-risk and high-volume. Support triage for your top five intents is the obvious choice. Deflect things like "Where's my order?" and "How do I reset my password?" so your humans can handle the messy, complex stuff. Measure deflection rate or average handle time.
Although Klarna had somewhat reversed their AI-First approach following customer feedback, their assistant now handles sizeable chat volume with faster resolutions than before. That's not a demo - it's proof that tight scoping and clear measurement work.
Other low-regret starting points: invoice follow-ups (measure cycle time) or employee onboarding Q&A (measure time-to-complete).
Start boring. Prove the bones work. Then widen.
What Your Auditor Will Ask For (and How to Have It Ready)
You don't need a 40-slide governance framework (but if you want to build one, knock yourself out). You only need four things:
Access control — Least-privilege by default. No side doors, no shared credentials.
Written rules — "Cannot issue refunds over £25 without approval" is a rule. "Use good judgment" is not.
Audit trail — Every action logged with timestamp, reason code, and data accessed.
One-click rollback — Versioned workflows. Revert to last known good state while you debug.
Platforms like AgentKit give you this control plane out of the box. Bring this slide to every checkpoint meeting. When someone asks "but what if…?" you point at it.

What Your Auditor Will Ask For
What "Good" Looks Like (Four Lines You Track Every Week)
Once the pilot's running, you need to know if it's actually working - and you need to know fast. Forget model accuracy scores or technical metrics (okay, don't forget them!). Your management wants to see business outcomes.
Here's your dashboard during the pilot:
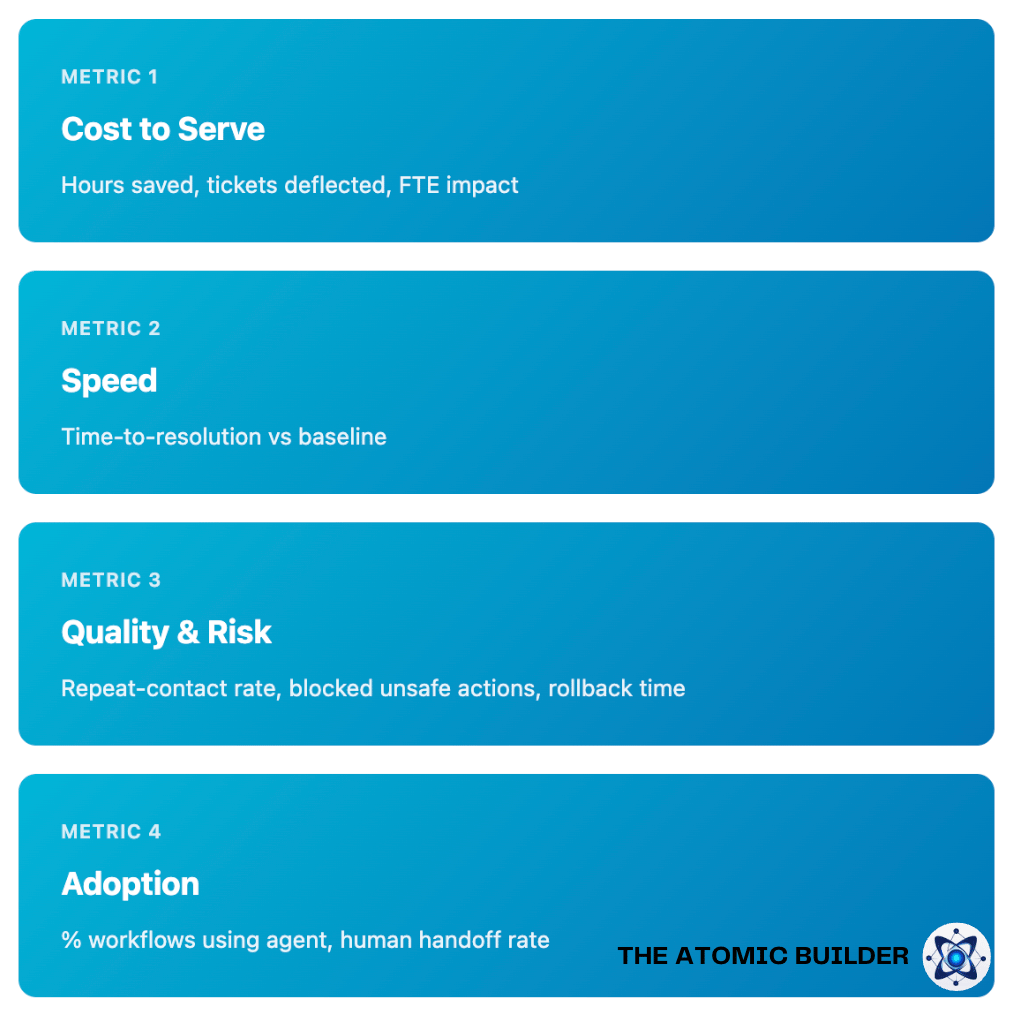
Measure what good looks like
These four lines are for your management. Keep them clean, keep them boring, and if one starts trending the wrong way, pause and fix it before you widen.
The Real Question
Don't ask whether AI can do it and if agents are worth it. Explore your use cases and then ask when your business should let them loose - and what proof earns that trust.
If the action is reversible, the rules are written down, and the KPI moves in testing, give your agent the keys. Just make sure there's a speed limiter, a logbook, and someone on-call who knows where the kill switch is!
That's how you go from "interesting demo" to "this is actually running in production and no one's panicking."
If this helped you, share it with someone on your team or in your org who's been asked "should we let an agent do that?" and doesn't know how to answer yet. See you next week! Faisal |  |
P.S. Know someone else who’d benefit from this? Share this issue with them.
Received this from a friend? Subscribe below.
The Atomic Builder is written by Faisal Shariff and powered by Atomic Theory Consulting Ltd — helping organisations put AI transformation into practice.